Une batterie de test pour du code Legacy en quelques minutes avec Approval Test
Si on doit travailler sur une appli existante, on essaie de ne rien casser, donc d’être sûr qu’il fait toujours la même chose. Donc on lui mets des milliers de trucs en entrées, on mesure les milliers d’autres trucs en sortie et on vérifie que même si on change des machins on a toujours pareil.
Il y a quelques temps, j’ai fait une présentation au JUG Toulouse.
L’idée, c’était de montrer en quelques minutes comment réaliser une batterie de tests pour du code legacy, en utilisant la librairie Approvals.
Et en passant, d’écrire des tests en Kotlin pour vérifier code en Java.
Code Legacy : qu’est ce que c’est ?
Du Code-Legacy, c’est quoi ?
C’est du code vieux ? existant ? avec des dépendances ? de mauvaise qualité ? du code dont on n’a pas les specs et dont on ne sait pas ce qu’il fait ?
Une bonne définition de Michael Feathers dit qu’il s’agit de code sans tests.
Du code-legacy, c’est aussi du code qui est en production et qui est utilisé.
Et comme “un bug suffisament vieux devient une feature”, il ne faut rien changer au fonctionnement actuel.
Pour pouvoir rajouter une nouvelle fonctionnalité, il faut avoir une base de code propre et être sûr que la nouveauté ne casse pas l’existant.
Golden Master Test
Le Golden Master Test, ou approvals tests, ou test boite noire, c’est une méthode qui vise à considérer le système à tester comme une boite noire et à vérifier que l’on obtient toujours les mêmes sorties quand on y applique les mêmes entrées.
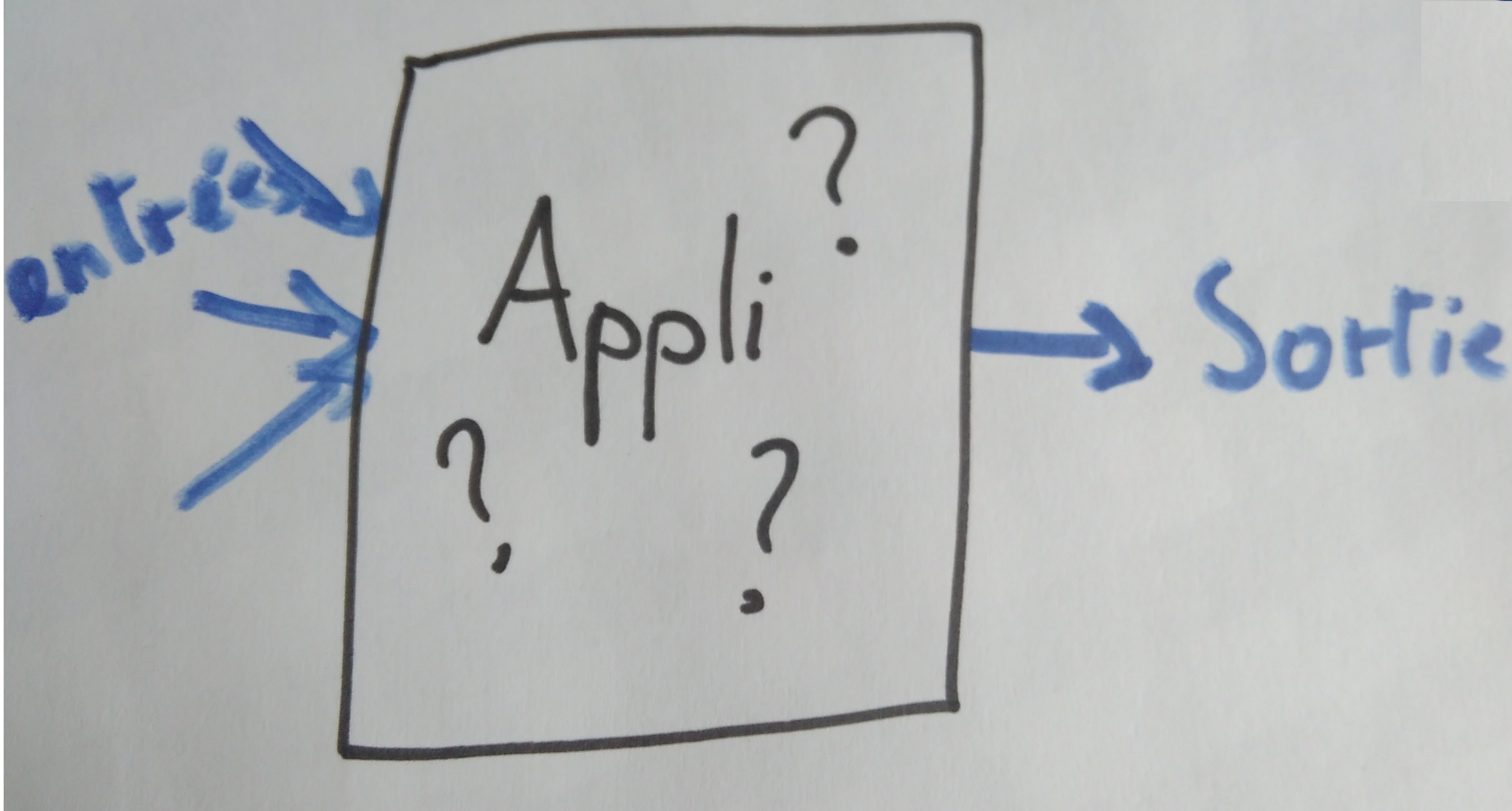
Concrètement, comment on peut faire ça ?
Il faut pouvoir isoler toutes les entrées quelques part, pour les reproduire et les faire varier.
Et il faut pouvoir comparer facilement les sorties. Une astuce, c’est de sérialiser les sorties pour ne comparer que du texte.
(voir, utiliser les logs comme des sorties)
Et pour ne pas y passer des heures, il est bien de pouvoir générer facilement toutes les entrées.
Limites
Un Golden-Master test ne donne aucune specs, aucune information fonctionnelle sur ce que fait l’application. On sait juste que pour un set d’entrées donné elle aura toujours le même fonctionnement.
Pour vérifier si le test teste tout, une solution est de regarder la couverture de code. Mais comme tout indicateur, il est à prendre pour ce qu’il est : la couverture nous permet de dire que le test utilise cette partie du code, mais pas qu’on en vérifie forcément bien le fonctionnement.
Une autre solution est de modifier (soit à la main, soit avec plein d’outils de mutation testing) des bouts de code de prod, en remplaçant un + par un -, en changeant des chiffres, des chaines de caractères. Et en théorie, si le test sert à quelque chose, il devrait passer au rouge et indiquer que l’une des sorties n’est plus comme avant.
Faire échouer le test, c’est la partie “Red” du TDD et c’est nécessaire pour être sûr que notre test sert à quelque chose. C’est un peu tester le test.
Avant de pouvoir utiliser cette technique, il faut réussir à supprimer les dépendances, pour que le test soit reproductible, sans avoir besoin de base de données. Et sans faire d’appel à l’extérieur.
Il peut être intéressant aussi de mocker les horloges, pour pouvoir comparer des logs sans être géné par les dates et heures qui varient.
Approvals
Approvals est une librairire qui permet fait principalement deux choses :
- comparer un fichier avec un fichier de référence
- générer toutes les combinatoires possibles avec des listes de paramètres d’entrée
En soit, ce n’est pas indispensable et ça ne doit pas être très compliqué de recoder ça soit même. (de même qu’un framework de test, c’est juste une fonction qui compare deux valeurs, avec beaucoup de sucre syntaxique autour !)
Mais c’est bien fait et assez pratique et c’est porté dans plein de langages (Java, Python, C++, Swift, php, .Net, …)
C’est OpenSource et il est donc possible de l’améliorer ou le porter dans un autre langage.
Le Kata : Gilded Rose
C’est un best-seller des katas de refactoring. Il représente une salle de vente de jeux de rôles, façon WoW.
On a des objets, qui ont une qualité et une date de péremption et quand le temps passe, le prix monte ou descend, selon le type d’objet (les objets “classiques” s’usent avec le temps, le fromage s’affine …).
Ce Kata a été porté en plus de 35 langages différents et est disponible sur Github. Il a été originellement créée par Terry Hughes et popularisé par Emily Bache.
Il n’y a pas d’effets de bord, donc facile pour mettre en place des tests boite noire.
Le code en lui même est un ramassis de if imbriqués, tous dans une seule énorme fonction, mais fait moins d’une centaine de lignes.
class GildedRose {
Item item;
public GildedRose(Item item) {
this.item = item;
}
public void updateQuality() {
if (!item.name.equals("Aged Brie")
&& !item.name.equals("Backstage passes to a TAFKAL80ETC concert")) {
if (item.quality > 0) {
if (!item.name.equals("Sulfuras, Hand of Ragnaros")) {
item.quality = item.quality - 1;
}
}
} else {
if (item.quality < 50) {
item.incrementQuality();
if (item.name.equals("Backstage passes to a TAFKAL80ETC concert")) {
if (item.sellIn < 11) {
if (item.quality < 50) {
item.incrementQuality();
}
}
if (item.sellIn < 6) {
if (item.quality < 50) {
item.incrementQuality();
}
}
}
}
}
if (!item.name.equals("Sulfuras, Hand of Ragnaros")) {
item.sellIn = item.sellIn - 1;
}
if (item.sellIn < 0) {
if (!item.name.equals("Aged Brie")) {
if (!item.name.equals("Backstage passes to a TAFKAL80ETC concert")) {
if (item.quality > 0) {
if (!item.name.equals("Sulfuras, Hand of Ragnaros")) {
item.quality = item.quality - 1;
}
}
} else {
item.quality = item.quality - item.quality;
}
} else {
if (item.quality < 50) {
item.incrementQuality();
}
}
}
}
}
Pas à Pas
On commence par tester un cas :
On essaie de voir ce qu’il se passe quand on a un objet avec un nom (mettons “fooo”), une qualité de départ (mettons 5) et un sell-in (le temps restant avant la date de péremption, mettons 5).
On met n’importe quoi en expected, puisqu’on ne sait pas le résultat attendu.
@Test
fun should_store_an_item() {
val gildedRose = GildedRose(Item("fooo", 5, 5))
assertThat(gildedRose.item.toString()).isEqualTo("we don't know yet")
}
Quand on lance le programme avec ces paramètres et que l’on regarde, on a en sortie la sérialization de l’objet, qui n’a pas été changé, ce qui nous permet donc de définir le résultat attendu.

@Test
fun should_store_an_item() {
val gildedRose = GildedRose(Item("fooo", 5, 5))
assertThat(gildedRose.item.toString()).isEqualTo("Item{name='fooo', sellIn=5, quality=5}")
}
Puis un deuxième cas,
On peut ensuite écrire un autre test, en updatant la qualité.
Idem, on regarde ce que nous donne l’application pour avoir une idée du résultat attendu. On a donc en sortie la sérialization de l’objet, mais avec une qualité et un sell-in de 4 au lieu de 5.
@Test
fun should_store_an_item_and_update_its_quality() {
val gildedRose = GildedRose(Item("fooo", 5, 5))
gildedRose.updateQuality()
assertThat(gildedRose.item.toString()).isEqualTo(Item("fooo", 4, 4).toString())
}
On écrit plein d’autres tests
On peut ensuite updater la qualité deux fois, trois fois … et voir comment ça évolue.
Ou faire changer les paramètres initiaux :
- changer de type d’objet, de nom : si on met “Aged Brie”, que se passe t-il ? la qualité augmente, mais le sell-in baisse.
- changer de qualité de départ,
- changer de sell-in (il semble y avoir un cas limite à 0 ?)
Une solution pour optimiser, serait d’extraire le test dans une méthode à part, ça permet d’écrire plus facilement les tests et ils sont plus lisibles.
@Test
fun should_store_an_item_and_update_its_quality_7_times() {
val actual = runApp(itemName = "Basic Item", sellIn = 3, quality = 10, nbOfUpdates = 7)
assertThat(actual).isEqualTo("Item{name='Basic Item', sellIn=-4, quality=0}")
}
@Test
fun should_store_an_item_and_update_its_quality_7_times_with_a_long_sell_in() {
val actual = runApp("Basic Item", 30, 10, 7)
assertThat(actual).isEqualTo("Item{name='Basic Item', sellIn=23, quality=3}")
}
@Test
fun should_store_a_Backstage_Pass_and_update_its_quality_8_times() {
val actual = runApp("Backstage passes to a TAFKAL80ETC concert", 5, 5, 8)
assertThat(actual).isEqualTo("Item{name='Backstage passes to a TAFKAL80ETC concert', sellIn=-3, quality=0}")
}
private fun runApp(itemName: String, sellIn: Int, quality: Int, nbOfUpdates: Int)
: String {
val item = Item(itemName, sellIn, quality)
val gildedRose = GildedRose(item)
(1..nbOfUpdates).forEach { gildedRose.updateQuality() }
return gildedRose.item.toString()
}
Mais à écrire les tests à la main, et recopier l’expected à chaque fois, c’est long.
Surtout que potentiellement, on a beaucoup de combinatoires : il y a 4 types d’objets, la qualité de départ, le sell-in de départ et le nombre d’update sont des entiers. Si on les limite entre 0 et 99, on a donc 4 x 100 x 100 x 100 = 4 000 000
4 millions de tests ! on ne va pas les écrire un par un !
Mise en place d’Approvals
C’est là qu’Approvals rentre en jeu.
On ajoute la lib à Graddle :
testCompile 'com.approvaltests:approvaltests:2.0.0'
On défini des tableaux de valeurs possibles pour les paramètres d’entrées. Ou des ranges pour les entiers.
Et on appelle la méthode en utilisant LegacyApprovals.LockDown(...) et en définissant la méthode à appeler et les paramètres.
@Test
fun should_always_have_the_same_result() {
val names = arrayOf("some item", "Aged Brie", "Sulfuras, Hand of Ragnaros")
val sellIns = Range.get(1, 25)
val qualities = Range.get(1, 25)
val nbOfUpdates = Range.get(1, 75)
LegacyApprovals.LockDown(
this, "runApp",
names,
sellIns,
qualities,
nbOfUpdates
)
}
public fun runApp(
itemName: String,
sellIn: Int?,
quality: Int?,
nbOfUpdates: Int?
): String? {
val item = Item(itemName, sellIn!!, quality!!)
val gildedRose = GildedRose(item)
(1..nbOfUpdates!!).forEach { gildedRose.updateQuality() }
return gildedRose.item.toString()
}
La lib est en Java, et malgré l’interopérabilité Kotlin-Java, il y a quelques changements à faire, surtout pour la gestion des objets nulls (les ? et !!).
De plus, tout n’est pas parfait (mais c’est open-source, on peut améliorer !), donc la méthode est définie par son nom en String
Lancement d’Approvals
Le test se lance comme n’importe quel autre test.
Et il échoue.
Parce qu’Approvals génère tous les cas de tests et les compare à une référence, qui n’existe pas.
Il faut donc accepter de ce résultat comme étant la référence.
(pour ubuntu, Approvals donne une ligne de commande à executer pour copier le fichier reçu à la destination de la référence)
Approvals utilise donc deux fichiers :
- GildedRoseTest.should_always_have_the_same_result.approved.txt
- GildedRoseTest.should_always_have_the_same_result.received.txt
Le premier (NomDeLaClasseDeTest.nom_de_la_methode_de_test.approved.txt) contient les valeurs de références, donc tous les cas générés. Avec l’exemple de code du dessus, celà représente plus de 14 000 cas de tests.
Si on l’ouvre, on voit qu’il contient la définition des paramètres et le résultat.
[some item, 6, 4, 1] = Item{name='some item', sellIn=5, quality=3}
[Aged Brie, 6, 4, 1] = Item{name='Aged Brie', sellIn=5, quality=3}
[Sulfuras, Hand of Ragnaros, 6, 4, 1] = Item{name='Sulfuras, Hand of Ragnaros', sellIn=6, quality=4}
[some item, 7, 4, 1] = Item{name='some item', sellIn=6, quality=3}
[Aged Brie, 7, 4, 1] = Item{name='Aged Brie', sellIn=6, quality=3}
Le deuxième fichier (NomDeLaClasseDeTest.nom_de_la_methode_de_test.received.txt) contient le résultat du test. Donc tant que le code est identique, il contient la même chose et est supprimé par Approvals aussitôt la comparaison effectuée.
On peut ensuite modifier tranquillement notre code de prod, on aura la certitude que pour le même set d’entrées, on aura les mêmes sorties.
Et si erreur il y a, Approvals nous montrera la différence :
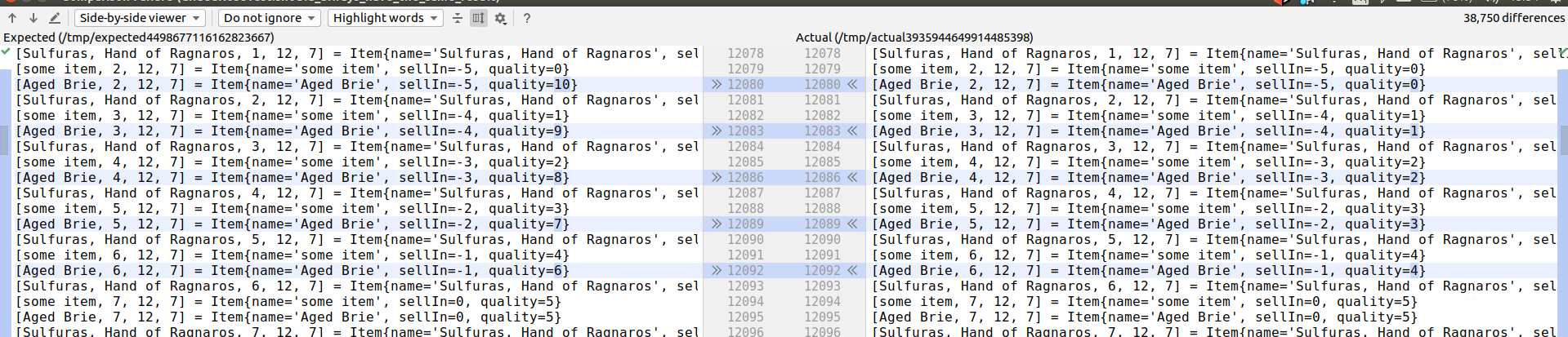
Limitations
Approvals est une lib Open-source, n’évoluant pas beaucoup.
Sa syntaxe n’est pas des plus claire, surtout en l’utilisant en Kotlin. Il y aurait moyen de l’améliorer un peu (les noms de méthodes en string, la nullabilité).
Là, l’exemple est simple : pas d’effets de bord et surtout une sortie en String. Dans d’autres cas réels, il faut trouver le moyen de sérialiser les sorties. Ou comparer des logs ?
Je n’ai pas vu d’option permettant d’exclure certaines parties du fichier à comparer, pour ne pas être gêné par des horloges ou du random par exemple.
La combinatoire et la sérialisation peuvent très vite faire des très gros fichiers impossibles à comparer. Par exemple, si on teste avec les 4 millions de possibilités, ça fait un fichier trop gros et Approvals buggue et ne compare plus. Il est donc nécessaire de découper en plusieurs tests.
Et surtout, un test ne dit pas qu’il n’y a pas de bug, uniquement que ce qui est testé marche.
Potentiellement on oublie quand même certains cas.
Et les tests boite-noire ne donnent aucune specs. Uniquement de l’aide pour la non-régression.
Kotlin et Java
Bien que le code “de prod” soit en Java, les tests ont été écrits en Kotlin. Il n’y a rien à configurer ou à prévoir à part préciser que le projet utilise Kotlin.
J’ai utilisé Approvals qui est une librairie Java sans gros soucis (à part préciser que les types peuvent être nuls). Idem, j’ai utilisé pour la syntaxe des tests la librairie Java AssertJ. Il n’y a absolument rien à faire pour l’utiliser en Kotlin : on la rajoute au pom (ou graddle) tel un projet java, et on l’utilise.
On pourrait ensuite convertir tout le code de prod en Kotlin automatiquement grâce à IntelliJ (Ctrl- Alt - Maj - K).
Références
Il y a un blog de Johan Martisson où il applique la même méthode, mais sur le kata Trivia.
C’est dans une de ses conférences que j’ai découvert cet outil il y a quelques années !